Learning 3D models of all animals on the Earth requires massively scaling up existing solutions. With this ultimate goal in mind, we develop 3D-Fauna, an approach that learns a pan-category deformable 3D animal model for more than 100 animal species jointly. One crucial bottleneck of modeling animals is the limited availability of training data, which we overcome by simply learning from 2D Internet images. We show that prior category-specific attempts fail to generalize to rare species with limited training images. We address this challenge by introducing the Semantic Bank of Skinned Models (SBSM), which automatically discovers a small set of base animal shapes by combining geometric inductive priors with semantic knowledge implicitly captured by an off-the-shelf self-supervised feature extractor. To train such a model, we also contribute a new large-scale dataset of diverse animal species. At inference time, given a single image of any quadruped animal, our model reconstructs an articulated 3D mesh in a feed-forward fashion within seconds.
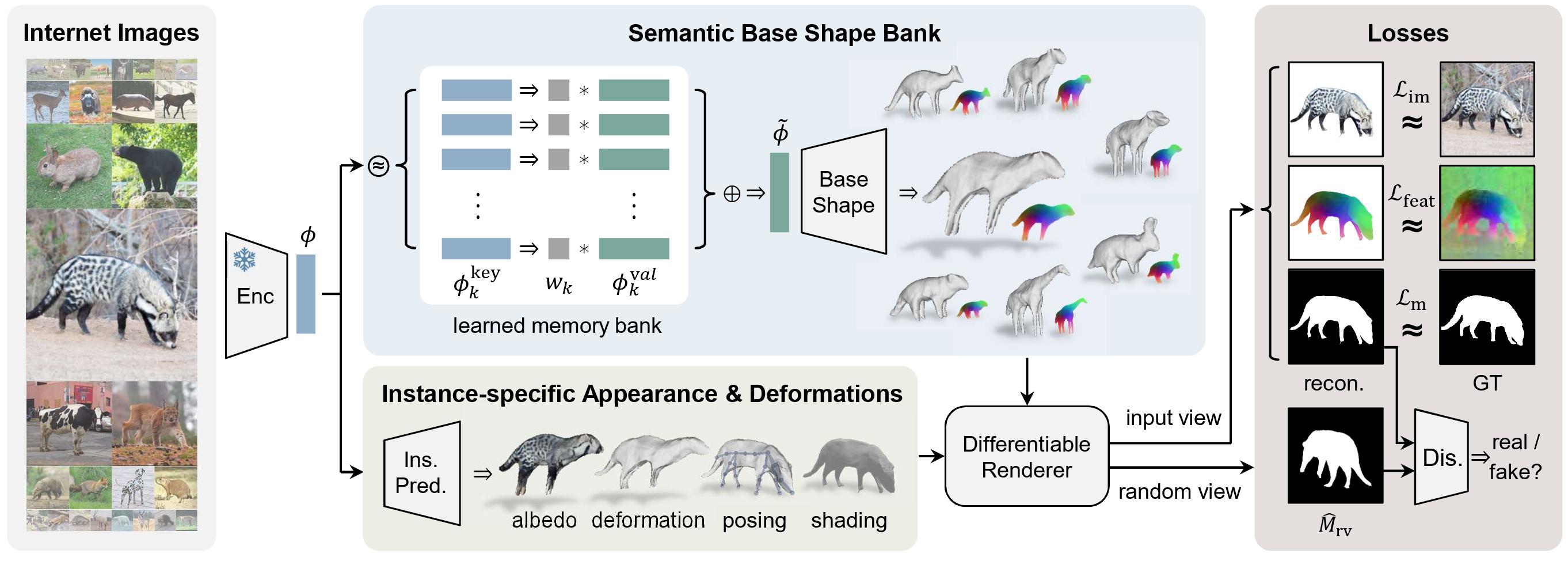
3D-Fauna is trained using only single-view images from the Internet. Given each input image, it first extracts a feature vector using a pre-trained unsupervised image encoder. This is then used to query a learned memory bank to produce a base shape and a DINO feature field in the canonical pose. The model also predicts the albedo, instance-specific deformation, articulated pose and lighting, and is trained via image reconstruction losses on RGB, DINO feature map and mask, as well as a mask discriminator loss, without any prior shape models or keypoint annotations.
Given a single image of any quadruped animal without any category information, the model reconstructs articulated 3D shape and appearance of it, which can be animated and re-rendered from arbitrary viewpoints.
We can also use one model to reconstruct different animals from video frames.
Our trained shape bank allows for interpolation between reconstructioned instances from different input images, which proves our shape space is continuous and smooth.
Try it yourself: Move the slider to interpolate shapes in the interpolated viewpoints (left) and a fixed viewpoint (right).



Input Image 0


Input Image 1



Input Image 0
Input Image 1



Input Image 0
Input Image 1



Input Image 0
Input Image 1



Input Image 0
Input Image 1
We can also directly sample numerous and diverse shapes from the trained shape bank.
@article{li2024learning,
title = {Learning the 3D Fauna of the Web},
author = {Li, Zizhang and Litvak, Dor and Li, Ruining and Zhang, Yunzhi and Jakab, Tomas and Rupprecht, Christian and Wu, Shangzhe and Vedaldi, Andrea and Wu, Jiajun},
journal = {arXiv preprint arXiv:2401.02400},
year = {2024}
}We are very grateful to Cristobal Eyzaguirre, Kyle Sargent, Yunhao Ge for insightful discussions, and Chen Geng for proofreading. The work is in part supported by the Stanford Institute for Human-Centered AI (HAI), NSF RI #2211258, ONR MURI N00014-22-1-2740, the Samsung Global Research Outreach (GRO) program, Amazon, Google, and EPSRC VisualAI EP/T028572/1.