|
I am a CS Ph.D. student at Stanford starting 2024 Fall, advised by Jiajun Wu. I am supported by the Stanford Graduate Fellowship. I got my M.Eng in Control Science and Engineering department from Zhejiang University in 2024, where I was advised by Prof. Yong Liu in April Lab. I obtained my B.Eng from the same department with an honor degree at Chu Kochen Honor College in 2021. In past years, I had the pleasure of collaborating with Shangzhe Wu and Prof. Jiajun Wu at Stanford University, Prof. Yiyi Liao at Zhejiang University, Prof. Jifeng Dai at Tsinghua University, Weichao Qiu and Prof. Alan Yuille at CCVL. Email / Google Scholar / Github / Twitter / LinkedIn |

Also check out: Kechun Xu. |
|
|
|
|

|
Zizhang Li*, Hong-Xing Yu*, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, Jiajun Wu ICCV, 2025, Highlight Project page / arXiv WonderPlay combines physical simulation and video generative prior to enable controllable and realistic interactions given user action input and only a single image. |

|
Yunzhi Zhang, Zizhang Li, Matt Zhou, Shangzhe Wu, Jiajun Wu CVPR, 2025, Highlight Project page / arXiv / Code The Scene Language is a visual scene representation that concisely and precisely describes the structure, semantics, and identity of visual scenes. It represents a scene with three key components: a program that specifies the hierarchical and relational structure of entities in the scene, words in natural language that summarize the semantic class of each entity, and embeddings that capture the visual identity of each entity. |

|
Yunzhi Zhang, Zizhang Li, Amit Raj, Andreas Engelhardt, Yuanzhen Li, Tingbo Hou, Jiajun Wu, Varun Jampani ECCV, 2024 Project page / arXiv 3D Congealing aligns semantically similar objects in an unposed 2D image collection to a canonical 3D representation, via fusing prior knowledge from a pre-trained image generative model and semantic information from input images. |

|
Zizhang Li*, Dor Litvak*, Ruining Li, Yunzhi Zhang, Tomas Jakab, Christian Rupprecht, Shangzhe Wu†, Andrea Vedaldi†, Jiajun Wu† CVPR, 2024 Project page / arXiv / Code / Video / Demo 3D-Fauna learns a pan-category deformable 3D model of more than 100 different animal species using only 2D Internet images as training data, without any prior shape models or keypoint annotations. At test time, the model can turn a single image of an quadruped instance into an articulated, textured 3D mesh in a feed-forward manner, ready for animation and rendering. |

|
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry Lagun, Li Fei-Fei, Deqing Sun, Jiajun Wu CVPR, 2024 Project page / arXiv / code We train a 3D-aware diffusion model, ZeroNVS on a mixture of scene data sources that capture object-centric, indoor, and outdoor scenes. This enables zero-shot SDS distillation of 360-degree NeRF scenes from a single image. Our model sets a new state-of-the-art result in LPIPS on the DTU dataset in the zero-shot setting. We also use the MipNeRF-360 dataset as a benchmark for single-image NVS. |
  |
Zizhang Li, Xiaoyang Lyu, Yuanyuan Ding, Mengmeng Wang, Yiyi Liao†, Yong Liu† ICCV, 2023 arXiv / code We investigate the existing problems in SDF-based object compositional reconstruction under the partial observation, and propose different regularizations following the geometry prior to reach a clean and water-tight disentanglement. |

|
Xiaoyang Lyu, Peng Dai, Zizhang Li, Dongyu Yan, Yi Lin, Yifan Peng, Xiaojuan Qi ICCV, 2023 Project page / arXiv / code We study and analyze several key observations in indoor scene SDF-based volume rendering reconstruction methods. Upon those observations, we push forward an Occ-SDF hybrid representation for better reconstruction performance. |
|
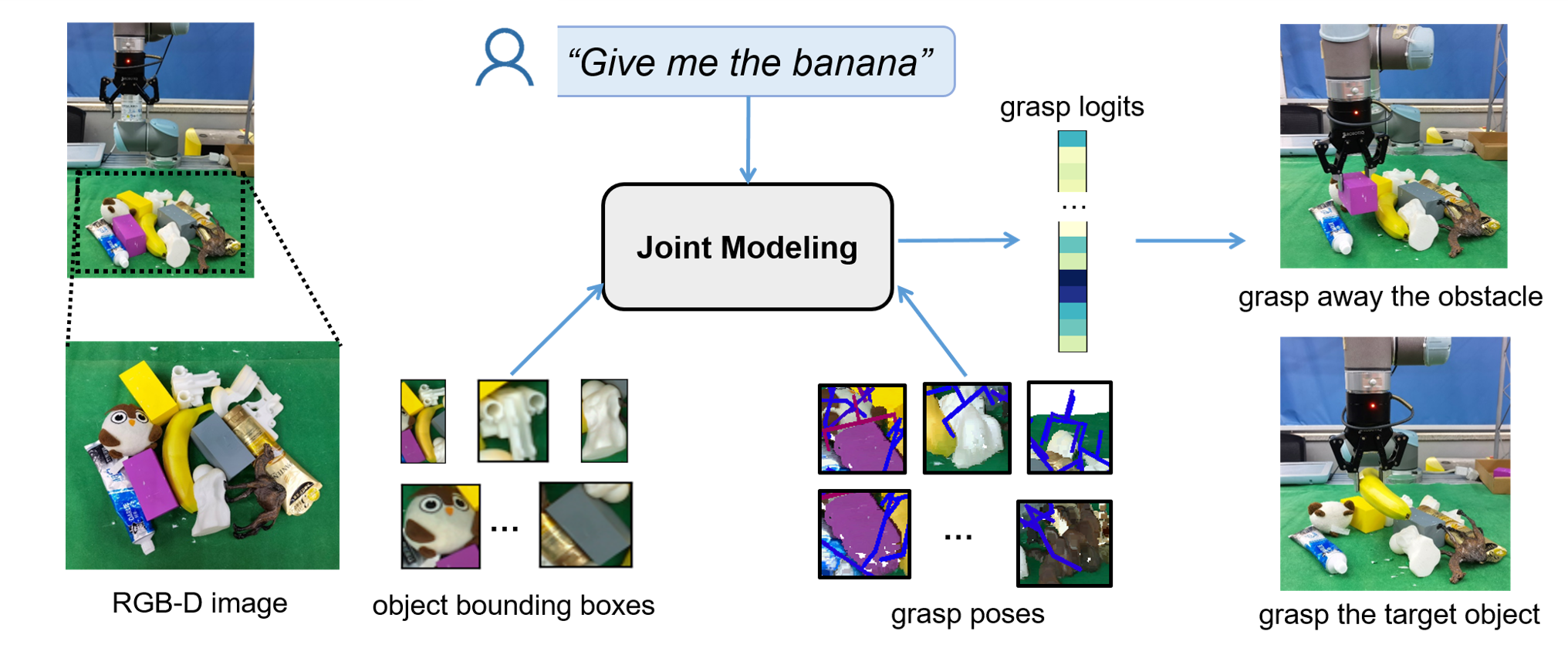
Kechun Xu, Shuqi Zhao, Zhongxiang Zhou, Zizhang Li, Huaijin Pi, Yifeng Zhu, Yue Wang, Rong Xiong ICRA, 2023 arXiv / code We propose to jointly model vision, language and action with object-centric representations for the task of language-conditioned grasping in clutter. |
|
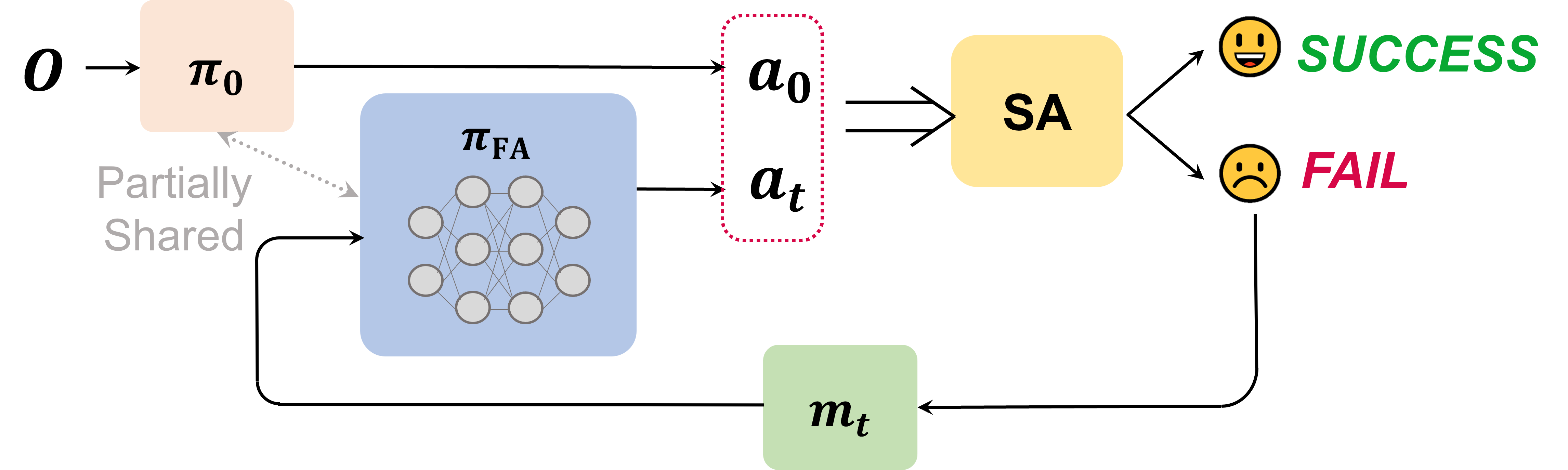
Kechun Xu, Runjian Chen, Shuqi Zhao, Zizhang Li, Hongxiang Yu, Ci Chen, Yue Wang, Rong Xiong ICRA, 2023 arXiv We investigate the dependency between the self-assessment results and remaining actions by learning the failure-aware policy, and propose two policy architectures. |
|
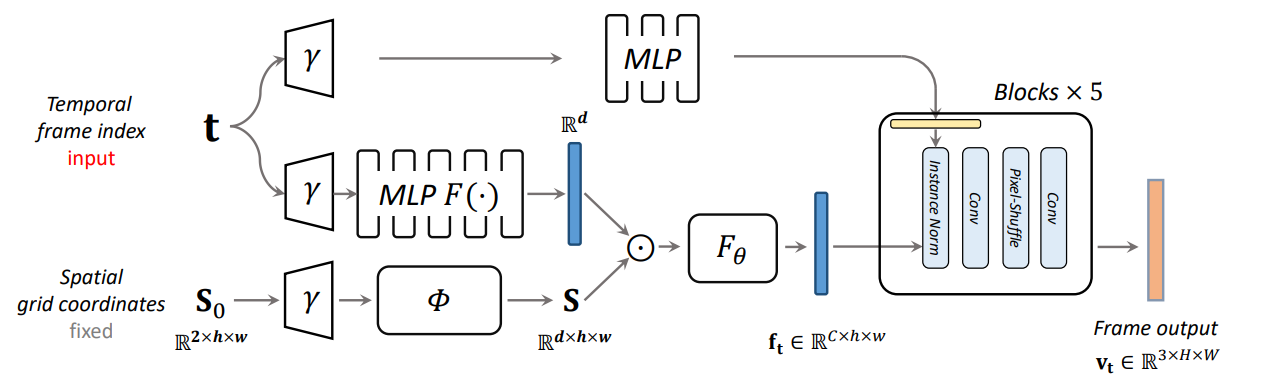
Zizhang Li, Mengmeng Wang, Huaijin Pi, Kechun Xu, Jianbiao Mei, Yong Liu ECCV, 2022 arXiv / code We investigate the architecture of frame-wise implicit neural video representation and upgrade it by removing a large portion of redundant parameters, and re-design the network architecture following a spatial-temporal disentanglement motivation. |

|
Qing Liu, Adam Kortylewski, Zhishuai Zhang, Zizhang Li, Mengqi Guo, Qihao Liu, Xiaoding Yuan, Jiteng Mu, Weichao Qiu, Alan Yuille CVPR, 2022, oral arXiv / code We construct a synthetic multi-part dataset with different categories of objects, evaluate different part segmentation UDA methods with this benchmark, and also provide an improved baseline. |
|
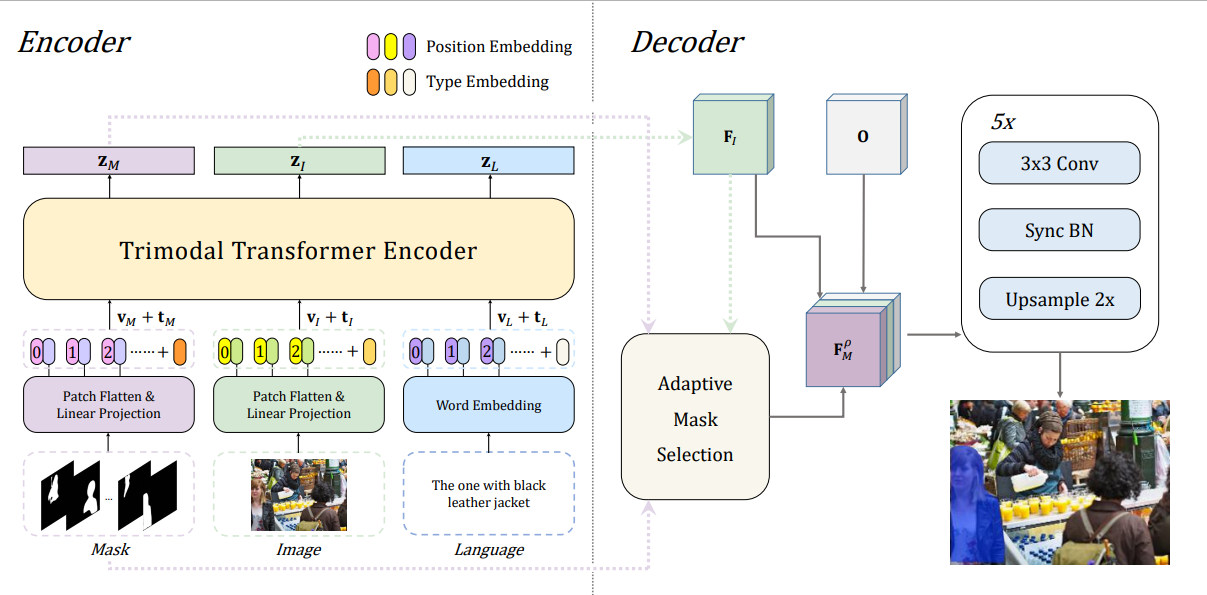
Zizhang Li*, Mengmeng Wang*, Jianbiao Mei, Yong Liu arxiv, 2021 arXiv We propose to regard the binary mask as a unique modality and train the tri-modal embedding space on top of ViLT for referring segmentation task. |
|
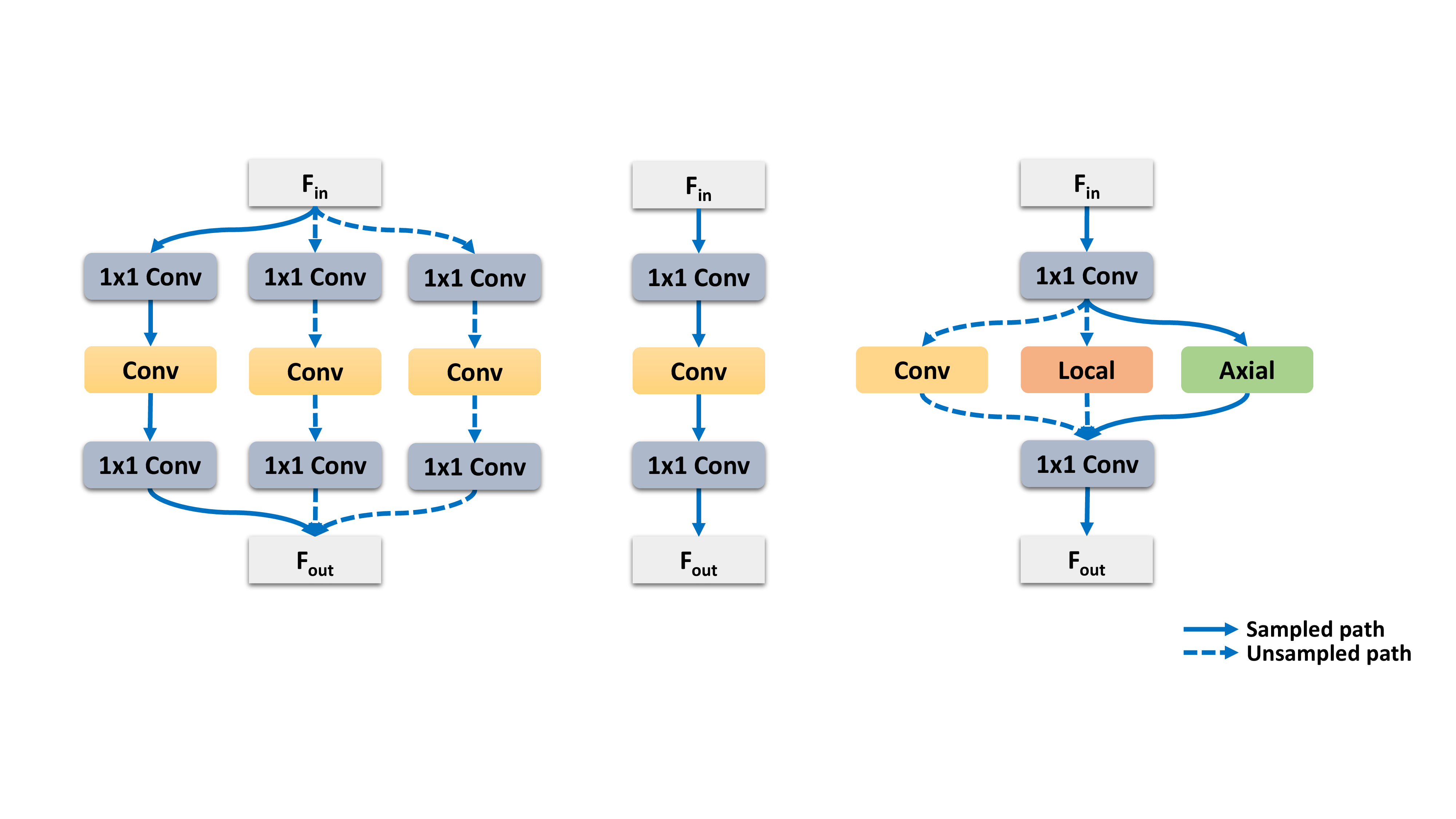
Huaijin Pi, Huiyu Wang, Yingwei Li, Zizhang Li, Alan Yuille BMVC, 2021 arXiv / code We propose a weight-sharing NAS method to combine convolution, local and global self-attention operators. |
|
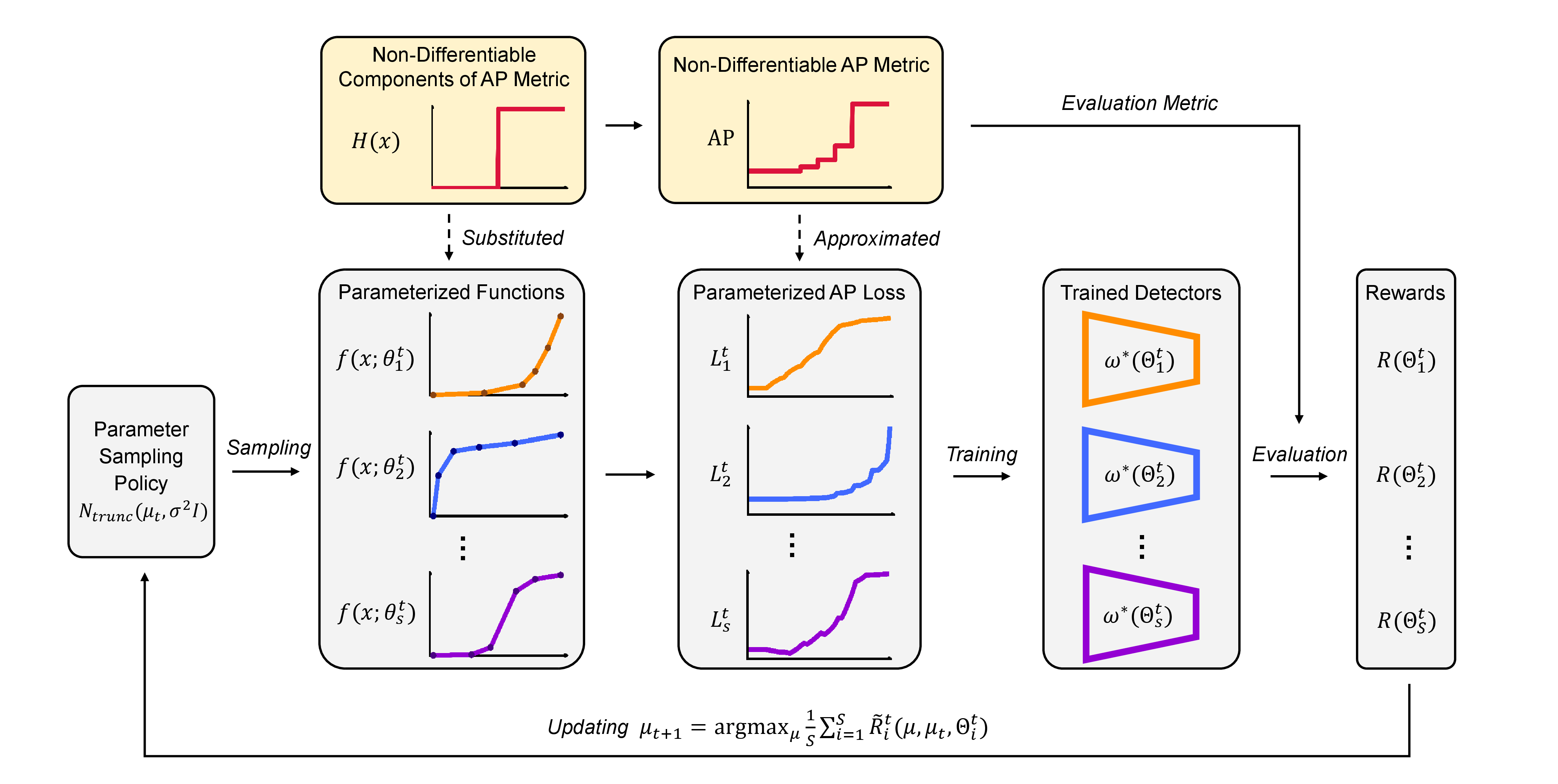
Chenxin Tao*, Zizhang Li*, Xizhou Zhu, Gao Huang, Yong Liu, Jifeng Dai NeurIPS, 2021 arXiv / code We transform the non-diffrentiable AP metric to differentiable loss function by utilizing Bezier curve parameterization. We further use PPO to search the parameters and show improved performance of the PAP loss on various detectors. |
|
|
|
This website is adapted from this amazing template |